AI infrastructure, One unified OS
You focus on creating amazing AI- We’ll handle the backend.

Latest News
View all posts


Our expertise
Transforming complex operation into simplicity
Backend.AI enables you to build, train, and serve AI models of any type any size, any scale. Run parallel computing jobs, train deep learning models, and deploy inference services within the same unified environment at ease. From fractional GPU sharing to multi-node clusters with thousands of GPUs, optimize your infrastructure to get every last bit.

Buying GPUs is the easy part
The most common enterprise GPU infrastructure challenges and how Backend.AI solves them.
Not fully utilizing the deployed GPU
Billions invested in GPU infrastructure, yet utilization rarely exceeds 30%. Teams allocate 8 GPUs but only use 2, a pattern that repeats across the organization.
See our solution →
Fractional GPU: utilize every last unit
Partition physical GPUs into precise fractional slices for concurrent multi-user sharing. Compatible with all NVIDIA GPUs at less than 5% overhead.
Company A GPU utilization 30% → 85% (2.8×)
Difficult to share GPUs among multiple teams
Multiple teams share a GPU cluster without clear allocation policies. Urgent experiments stall while other teams hold idle resources.
See our solution →
4-tier multi-tenancy for fair allocation
Manage resources hierarchically across Organization, Department, Project, and User levels. Idle resources are automatically redistributed via dynamic allocation.
University B Automated resource management without administrator intervention
Cloud adoption is restricted
Handling sensitive information restricts the adoption of external cloud AI services. AI must be operated in air-gapped environments.
See our solution →
Fully independent air-gapped operation
Installation, model deployment, and updates all operate without internet connectivity. multi-layer security sandboxing meets finance and defense-grade requirements.
Bank C air-gapped LLM operation
Facing GPU pricing and supply shortage challenges
Rising GPU prices and supply shortages drive interest in AMD, Intel, and domestic NPUs, but platform dependencies make it difficult to break away from a specific ecosystem.
See our solution →
12+ vendors under one unified interface
The Hardware Abstraction Layer (HAL) manages NVIDIA, AMD, Intel, Google TPU, Rebellions, FuriosaAI, Tenstorrent, and more from a single control plane.
Company D to introduce domestically developed NPUs on Backend.AI for its GPUaaS business
Must keep up with growing GPU demands
AI service expansion demands more GPUs, but scaling from dozens to hundreds of nodes introduces complexity that existing tools cannot handle.
See our solution →
Sokovan Orchestrator scales with you
The Sokovan scheduler handles multi-node, multi-tenant workloads at any scale. GPU and storage infrastructure grows seamlessly without re-architecture.
University E to increase 256% of GPU Node
More teams, exponentially more chaos
As teams grow, priority conflicts and queue issues arise. Staff turnover also risks losing operational know-how.
See our solution →
Software that handles scalable infrastructure
Backend.AI automates GPU operations through policy-based management. Resource quotas, scheduling rules, and access controls are defined as policies, enabling efficient operations.
University F operates campus infrastructure with minimal staff
About our heart
Sokovan. Meet the real expert who knows AI workload
Introducing Sokovan, the most powerful containerized workload orchestrator for AI infrastructure, designed from the ground up with AI in mind. At its core is a manager-agent dual-layer scheduling system that maximizes hardware utilization, performance, and operational efficiency across multi-tenant environments.
Explore Sokovan →
From idle to ideal
Container-level GPU virtualization
Backend.AI's patented technology intercepts CUDA API calls inside containers to precisely control GPU resources at the software level. Multiple users safely share a single physical GPU while maintaining complete workload isolation.
400%
GPU utilization increase
75%
Infrastructure cost reduction
3
Patents (KR/US/JP)
GPU utilization comparison
Multi-user GPU sharing
User A
0.25 GPU
User B
0.5 GPU
User C
0.15 GPU
User D
0.1 GPU
Hardware freedom
A vendor-neutral platform that supports 12+ AI accelerators
Backend.AI manages 12+ AI accelerator types, including NVIDIA Blackwell, Intel Gaudi, AMD Instinct, Rebellions ATOM+, and FuriosaAI RNGD, through a Hardware Abstraction Layer (HAL) under a single unified interface. Develop, train, and deploy with the same workflow regardless of the underlying hardware.










An intelligent platform that understands storage
Any storage, one interface.
Access data the same way regardless of the storage backend: VAST, WEKA, PureStorage, IBM Storage Scale, and more. With NVIDIA GPUDirect Storage support, transfer data directly from storage to GPU memory.
Learn more →







Mind the gap
Complete AI environments in air-gapped networks
Reservoir AI (model hub) + Reservoir (package repository)
Keep AI models and tools up to date, even in air-gapped networks. Reservoir completes the software supply chain for isolated AI infrastructure.
Explore Reservoir →Air-Gapped Network Boundary
Backend.AI Control Plane
Control
Data
GPU Nodes
Intuitive web-based management
Lowering the barrier to GPU utilization and operations
Backend.AI WebUI lets you manage GPU clusters, monitor resources, and govern multi-tenant environments through a browser, with no CLI expertise needed. From session management to policy-based resource allocation, everything happens in one unified interface.
Explore WebUI →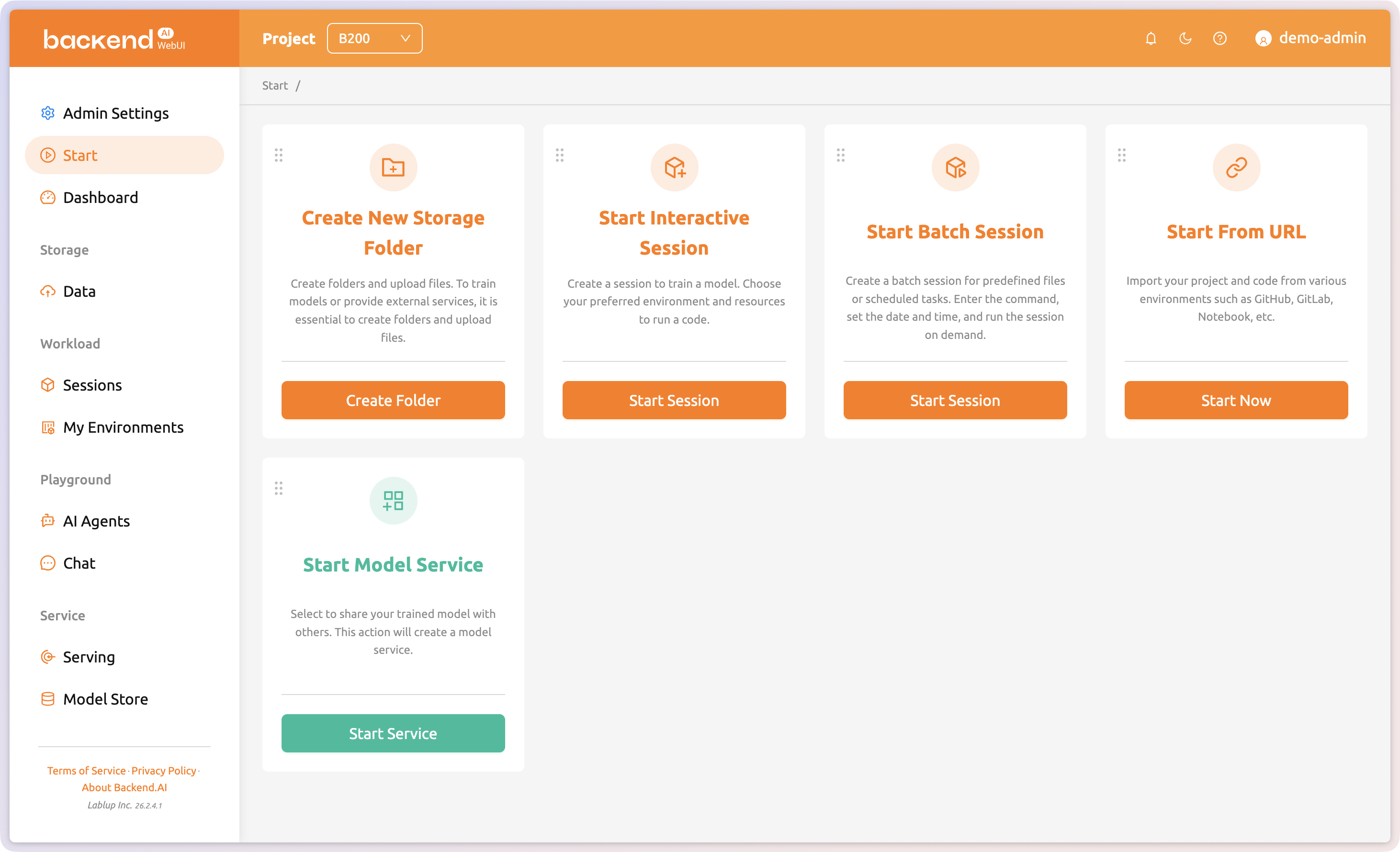
NVIDIA DGX-Ready Software
Built for NVIDIA DGX, certified to run at enterprise scale
As NVIDIA DGX-Ready Software, Backend.AI delivers seamless operation with NVIDIA DGX systems and Grace Blackwell. Container-level GPU virtualization combined with the Sokovan orchestrator optimizes utilization for AI and HPC workloads, in various scales.
Explore DGX-Ready →
Works the same in any environment
Choose the deployment model that fits your organization’s security policies and infrastructure: on-premises, cloud, or hybrid.
On-Premises
All data and workloads are processed within your own data center. Operate independently even in air-gapped environments.
- Full data sovereignty
- Air-gapped support
- Easy regulatory compliance
Cloud
Runs on GPU instances across public clouds like AWS, GCP, Azure, and OCI. Start immediately with zero upfront investment.
- Start instantly with no upfront cost
- Elastic scale up/down
- Instant global region deployment
Hybrid
Manage on-premises and cloud from a single control plane. Keep sensitive data on-premises while bursting workloads to the cloud.
- Unified single control plane
- Policy-based workload placement
- Protect existing on-prem investment
Dashboard & management
Monitor, manage, and control everything
| GPU | Model | Util | VRAM | Temp | Power |
|---|---|---|---|---|---|
| GPU | H200 141 | 79.1% | 84.2/141GB | 78°C | 511/700W |
| GPU | H200 141 | 28.8% | 90.0/141GB | 63°C | 420/700W |
| GPU | H200 141 | 36.1% | 61.6/141GB | 63°C | 385/700W |
| GPU | H200 141 | 66.2% | 69.3/141GB | 75°C | 502/700W |
The dashboard lets you monitor resource usage, session status, and infrastructure health at a glance. With All-SMI, you can monitor heterogeneous accelerators and servers including NVIDIA, AMD, Intel Gaudi, and Google TPU from a single interface. Team and user management features are built in for organizational control.
Learn about All-SMI →Trusted by industry leaders


VAST COSMOS
Technology Partner
Everpure
Tech Alliance Partner
Customers
Universities, research labs, and enterprises trust Backend.AI
From campus labs to enterprise data centers, over 120 organizations are experiencing the benefits of Backend.AI.

KT
Telecom/Cloud

KT Cloud
Telecom/Cloud

NHN Cloud
Telecom/Cloud

Samsung Electronics
IT/Electronics

LG Electronics
IT/Electronics

CJ AI Center
IT/Electronics

Shinhan Bank
Finance

Bank of Korea
Finance

Hyundai Mobis
Mobility

Korean Air
Airline

Samsung Welstory
Food

LIG Defense & Aerospace
Defense

ROK Navy
Defense

Gyeonggi Province
Government

Samsung Medical Center
Healthcare/Bio

CNUH
Healthcare/Bio

HIRA
Healthcare/Bio

Samsung Research
IT/Electronics

ETRI
Research/Public

KISTI
Research/Public
Univ. of Southern California
University
SKKU
University

Kookmin Univ.
University
And more...
Customer stories
Customer stories built with Backend.AI
Universities, research institutions, and enterprises worldwide are transforming their GPU infrastructure with Backend.AI
Lablup's cloud resources have streamlined our research operations. With Backend.AI's fast, convenient, and anywhere-accessible platform, our team maintains productivity regardless of location.
Dr. Cherlhyun Jeong, Chemical and Biological Integrative Research Center, CJLab, KIST
Read more→When we started with just three GPU servers, Backend.AI enabled 80+ students to run modeling exercises simultaneously by container-level GPU virtualization, all without dedicated administrative support.
Professor Yoonho Cho, AI, Big Data, and Convergence Management, KMU
Read more→Running a university supercomputing center prevents redundant spending and, with ongoing upgrades, will greatly boost research and hands-on learning across campus.
Director Hyoungkee Choi, Supercomputing Center, SKKU
Read more→If students cannot truly make use of the resources their school provides, then those resources do not truly serve the students. Backend.AI is an AI infrastructure operating platform that makes institutional resources both manageable and accessible.
Professor BD Kim, Associate Chief Research Information Officer
Read more→
We spent our time on development, not infrastructure, and Backend.AI handled the rest
Kyle Yi, Consortium Lead, Upstage
Read more→
askyour.trade 2.0 is an intelligent trade workspace where AI understands and makes autonomous decisions on documents. teamreboott, in collaboration with Lablup, is accelerating the digital transformation in trade operations.
Sungchul Choi, CEO, Teamreboott
Read more→