Engineering
Mar 29, 2024
Engineering
Deconstructing a working Raft implementation - 1

Gyubong Lee
Software Engineer
Mar 29, 2024
Engineering
Deconstructing a working Raft implementation - 1
Gyubong Lee
Software Engineer
- Deconstructing a working Raft implementation - 2
- Deconstructing a working Raft implementation - 1
- Introduce raftify: High-level Raft framework created with focusing on scalability
In this article, we'll assume that the reader has a theoretical background in Raft, and we'll dig into the tikv/raft-rs code to see how state machines in distributed systems actually synchronize and behave in a few brief scenarios.
While this article focuses on analyzing the RAFT-RS code, we will use the RAFTIFY source code as an example in some sections for a complete understanding, as the RAFT-RS implementation does not include network and storage layers for flexibility.
💡 raftify is a high-level Raft implementation developed by Lablup. In this post, I'm only going to describe raftify with minimal code to understand how raft works. If you're curious about raftify, check out this post.
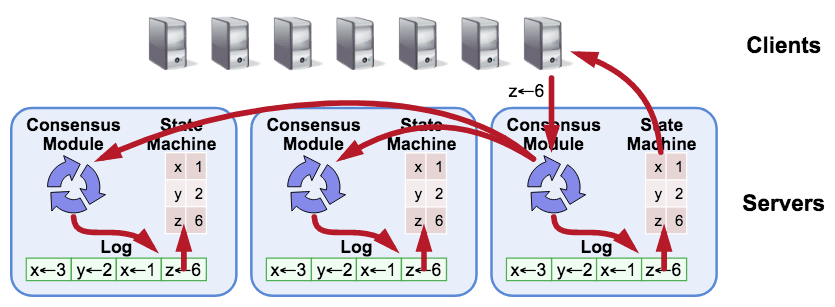
Img from: https://github.com/tikv/raft-rs
RAFT-RS architecture with a focus on ## types
Before we dive into the scenarios, let's take a quick look at the architecture, focusing on the typical types used in the code base.
Raft
The Raft object of each Raft node holds a message queue msgs in memory and interacts with other Raft nodes through this queue.
In a high-level implementation like raftify, the network layer is responsible for putting messages into this queue through an abstraction layer that will be described later.
This message queue can therefore be seen as an endpoint for communication, and the Raft implementation will process these messages according to its current state, maintaining a consistent state between nodes.
The RaftCore type holds the data corresponding to the state of this Raft node.
There is also a type called Progress that holds metadata for synchronizing log entries with other Raft nodes, and these are updated appropriately in the ProgressTracker depending on the situation.
As a result, Raft has the following types
// tikv/raft-rs/blob/master/src/raft.rs
pub struct Raft<T: Storage> {
pub msgs: Vec<Message>,
pub r: RaftCore<T>,
prs: ProgressTracker,
}RaftLog
Representative of the data that RaftCore has is RaftLog, which abstracts access to a sequence of log entries.
RaftLog<T: Storage> abstracts the types Unstable and T so that they can be handled together. Here, T corresponds to persistent storage that needs to be implemented at a higher level, such as raftify, and Unstable is a buffer that goes through before being written to this storage.
// tikv/raft-rs/blob/master/src/raft_log.rs
pub struct RaftLog<T: Storage> {
pub store: T,
pub unstable: Unstable,
...
}💡 If you're interested in learning more about the RaftCore type, check out this link.
Raft Loop
Raft implementations perform an iterative process of updating their state machine in an infinite loop in order to communicate with other Raft nodes and maintain a consistent state. In this article, we'll call this loop a Raft loop.
The source code for implementing a Raft loop in raftify is shown below.
(You can also see the example code in tikv/raft-rs if you want to see the most minimal implementation).
// lablup/raftify/blob/main/raftify/src/raft_node/mod.rs
async fn on_ready(&mut self) -> Result<()> {
if !self.raw_node.has_ready() {
return Ok(());
}
let mut ready = self.raw_node.ready();
if !ready.messages().is_empty() {
self.send_messages(ready.take_messages()).await;
}
if *ready.snapshot() != Snapshot::default() {
slog::info!(
self.logger,
"Restoring state machine and snapshot metadata..."
);
let snapshot = ready.snapshot();
if !snapshot.get_data().is_empty() {
self.fsm.restore(snapshot.get_data().to_vec()).await?;
}
let store = self.raw_node.mut_store();
store.apply_snapshot(snapshot.clone())?;
}
self.handle_committed_entries(ready.take_committed_entries())
.await?;
if !ready.entries().is_empty() {
let entries = &ready.entries()[..];
let store = self.raw_node.mut_store();
store.append(entries)?;
}
if let Some(hs) = ready.hs() {
let store = self.raw_node.mut_store();
store.set_hard_state(hs)?;
}
if !ready.persisted_messages().is_empty() {
self.send_messages(ready.take_persisted_messages()).await;
}
let mut light_rd = self.raw_node.advance(ready);
if let Some(commit) = light_rd.commit_index() {
let store = self.raw_node.mut_store();
store.set_hard_state_commit(commit)?;
}
if !light_rd.messages().is_empty() {
self.send_messages(light_rd.take_messages()).await;
}
self.handle_committed_entries(light_rd.take_committed_entries())
.await?;
self.raw_node.advance_apply();
Ok(())
}RawNode
Each Raft node has a higher-level instance of a type called RawNode that contains the Raft module.
A RawNode has a records field that represents the metadata of SoftState, a state that is kept only in memory, HardState, a state that is stored in persistent storage, and Ready, which is not yet stored.
💡 Ready is the data structure that is passed to the Raft node when it needs to be updated.
// tikv/raft-rs/blob/master/src/raw_node.rs
pub struct RawNode<T: Storage> {
pub raft: Raft<T>,
prev_ss: SoftState,
prev_hs: HardState,
max_number: u64,
records: VecDeque<ReadyRecord>,
commit_since_index: u64,
}In the first part of the Raft loop, when the ready method is called, the metadata from Ready is stored in records, and after all the snapshots, entries, etc. that need to be stored are processed, the last part of the loop, advance, calls commit_ready and updates the offset of the buffer Unstable.
RaftNode
A RaftNode is a type that raftify abstracts a RawNode at a higher level, integrating it with the network and storage layers.
In a separate asynchronous task, raftify receives messages sent by the gRPC client and passes them over the channel to the RaftNode.run task.
After processing the messages, it handles state changes in a function (Raft loop) named on_ready.
// lablup/raftify/blob/main/raftify/src/raft_node/mod.rs
pub async fn run(mut self) -> Result<()> {
let mut tick_timer = Duration::from_secs_f32(self.config.tick_interval);
let fixed_tick_timer = tick_timer;
let mut now = Instant::now();
loop {
...
tokio::select! {
msg = timeout(fixed_tick_timer, self.server_rcv.recv()) => {
if let Ok(Some(msg)) = msg {
self.handle_server_request_msg(msg).await?;
}
}
...
}
let elapsed = now.elapsed();
now = Instant::now();
if elapsed > tick_timer {
tick_timer = Duration::from_millis(100);
self.raw_node.tick();
} else {
tick_timer -= elapsed;
}
self.on_ready().await?
}
}To explain raftify's implementation in more detail, raftify iterates through the following process
- generate a request from the client (e.g. call
RaftServiceClient.proposeorRaftNode.propose) RaftServiceClient.proposeon the remote Raft node is called via gRPC.- RaftServiceClient.propose
passes theProposemessage over the channel to theRaftNode.run` coroutine. 4. RaftNode.runpolls the message queue and callsRawNode::proposewhen it receives aProposemessage.- when there are changes to the state machine that need to be applied, a
Readyinstance is created and passed to theon_readyhandler. - when entries are committed, the
on_readyhandler processes the committed entries and responds to the client.
With the theoretical stuff out of the way, let's analyze a few scenarios and see what happens.
💡 What we arbitrarily call Propose messages in this paragraph is a type of message defined for the purpose of proposing a state change to the cluster.
Scenario analysis.
1 - Add a new log entry
What happens under the hood when you request (propose) a change to the cluster to alter its state machine?
In this section, we'll break down what happens when you call RawNode.propose.
Here's a look at the RawNode.propose function
// tikv/raft-rs/blob/master/src/raw_node.rs
pub fn propose(&mut self, context: Vec<u8>, data: Vec<u8>) -> Result<()> {
let mut m = Message::default();
m.set_msg_type(MessageType::MsgPropose);
m.from = self.raft.id;
let mut e = Entry::default();
e.data = data.into();
e.context = context.into();
m.set_entries(vec![e].into());
self.raft.step(m)
}From the code above, you can see that the propose function calls step to make it handle a message of type MsgPropose.
Here, step is the function that corresponds to the actual message handler in raft-rs. If the node calling step is the leader, step_leader is called, if it is a follower, step_follower is called, and if it is a candidate, step_candidate is called.
The code for step is quite complex, but let's follow the code to see how the MsgPropose type is handled on the leader node.
// tikv/raft-rs/blob/master/src/raft.rs
fn step_leader(&mut self, mut m: Message) -> Result<()> {
...
match m.get_msg_type() {
MessageType::MsgPropose => {
...
if !self.append_entry(m.mut_entries()) {
...
}
self.bcast_append();
return Ok(());
}
...
}
}Raft.append_entrycallsRaftLog.append to add an entry. RaftLog.append appends the entries added to the Unstable buffer by self.unstable.truncate_and_append.
// tikv/raft-rs/blob/master/src/raft_log.rs
pub fn append(&mut self, ents: &[Entry]) -> u64 {
...
self.unstable.truncate_and_append(ents);
self.last_index()
}As previously described, the entries added to the buffer will be persisted in a Raft loop, and updating the state machine via an advance-like function will automatically update the offset and clear the buffer.
Let's take a look at the next call, bcast_append.
You can see that we're calling core.send_append with each follower's progress as an argument, using the ProgressTracker (prs) described in the previous section to synchronize the log entries of the leader and followers.
// tikv/raft-rs/blob/master/src/raft.rs
pub fn bcast_append(&mut self) {
let self_id = self.id;
let core = &mut self.r;
let msgs = &mut self.msgs;
self.prs
.iter_mut()
.filter(|&(id, _)| *id != self_id)
.for_each(|(id, pr)| core.send_append(*id, pr, msgs));
}The send_append has the following simple structure
// tikv/raft-rs/blob/master/src/raft.rs
fn send_append(&mut self, to: u64, pr: &mut Progress, msgs: &mut Vec<Message>) {
self.maybe_send_append(to, pr, true, msgs);
}The maybe_send_append reads the log entries in the range pr.next_idx to to via RaftLog.entries and passes them to prepare_send_entries.
(As you can infer from the maybe_ prefix to its name, the function returns true on success and false on failure.)
// tikv/raft-rs/blob/master/src/raft.rs
fn maybe_send_append(
&mut self,
to: u64,
pr: &mut Progress,
allow_empty: bool,
msgs: &mut Vec<Message>,
) -> bool {
...
let ents = self.raft_log.entries(
pr.next_idx,
self.max_msg_size,
GetEntriesContext(GetEntriesFor::SendAppend {
to,
term: self.term,
aggressively: !allow_empty,
}),
);
...
match (term, ents) {
(Ok(term), Ok(mut ents)) => {
if self.batch_append && self.try_batching(to, msgs, pr, &mut ents) {
return true;
}
self.prepare_send_entries(&mut m, pr, term, ents)
}
...
}
...
self.send(m, msgs);
true
}Prepare_send_entriescreates a message object m of typeMsgAppendand puts the entries into the message. It then updatesprogress` and returns it.
// tikv/raft-rs/blob/master/src/raft.rs
fn prepare_send_entries(
&mut self,
m: &mut Message,
pr: &mut Progress,
term: u64,
ents: Vec<Entry>,
) {
m.set_msg_type(MessageType::MsgAppend);
m.index = pr.next_idx - 1;
m.log_term = term;
m.set_entries(ents.into());
m.commit = self.raft_log.committed;
if !m.entries.is_empty() {
let last = m.entries.last().unwrap().index;
pr.update_state(last);
}
}Then self.send(m, msgs) puts this prepared message into the msgs message queue.
// tikv/raft-rs/blob/master/src/raft.rs
fn send(&mut self, mut m: Message, msgs: &mut Vec<Message>) {
...
msgs.push(m);
}The MsgAppend message that enters the message queue will be sent to the follower node from send_messages through the network layer. Therefore, we need to see how the follower node handles the MsgAppend message after receiving it.
Next, let's take a look at what happens on the follower node To find out what happens when a follower node receives an MsgAppend message, we can look at step_follower.
// tikv/raft-rs/blob/master/src/raft.rs
fn step_follower(&mut self, mut m: Message) -> Result<()> {
match m.get_msg_type() {
...
MessageType::MsgAppend => {
self.election_elapsed = 0;
self.leader_id = m.from;
self.handle_append_entries(&m);
}
...
}
}From the code above, you can see that the follower node that received the MsgAppend message is calling handle_append_entries.
This function creates a to_send, a message of type MsgAppendResponse, and calls RaftLog.maybe_append, as shown below.
// tikv/raft-rs/blob/master/src/raft.rs
pub fn handle_append_entries(&mut self, m: &Message) {
...
let mut to_send = Message::default();
to_send.to = m.from;
to_send.set_msg_type(MessageType::MsgAppendResponse);
if let Some((_, last_idx)) = self
.raft_log
.maybe_append(m.index, m.log_term, m.commit, &m.entries)
{
...
// MsgAppend 메시지를 수신
} else {
...
// MsgAppend 메시지를 거절
}
...
self.r.send(to_send, &mut self.msgs);
}This function calls match_term to check if the message's logTerm and the log entry's term values are the same, calls find_conflict to check for conflicts in the log entry sequence, and calls Raft.append if it determines there are no problems.
// tikv/raft-rs/blob/master/src/raft.rs
pub fn maybe_append(
&mut self,
idx: u64,
term: u64,
committed: u64,
ents: &[Entry],
) -> Option<(u64, u64)> {
if self.match_term(idx, term) {
let conflict_idx = self.find_conflict(ents);
if conflict_idx == 0 {
} else if conflict_idx <= self.committed {
fatal!(
self.unstable.logger,
"entry {} conflict with committed entry {}",
conflict_idx,
self.committed
)
} else {
let start = (conflict_idx - (idx + 1)) as usize;
self.append(&ents[start..]);
if self.persisted > conflict_idx - 1 {
self.persisted = conflict_idx - 1;
}
}
let last_new_index = idx + ents.len() as u64;
self.commit_to(cmp::min(committed, last_new_index));
return Some((conflict_idx, last_new_index));
}
None
}We've seen this function before. It was the last function called before the call to RaftLog.append when a log entry was proposed by the leader node.
As before, Raft.append_entry calls RaftLog.append to add the entry. RaftLog.appendappends the entries added to the Unstable buffer fromself.unstable.truncate_and_append`.
This outlines a scenario where logs added to the leader are persisted on the leader node and copied to the follower nodes.
2 - Leader and follower node log sequence mismatch
In scenario 1, we looked at the code assuming a normal situation, but in reality, issues such as network disconnection can cause mismatches between leader and follower nodes. Let's take another look at the code, this time focusing on how to detect and resolve mismatches between leader and follower nodes.
Let's say you have a cluster of three nodes that is processing thousands of requests that are successively changing the state machine, and then a network failure occurs.
In the event of a failure, we should start by looking at the logs written to the nodes, persisted log entries, and debugging information to get some context, but to avoid making this post too long, we'll just pick out the logs that will give us a general idea of what's happening on the nodes and analyze them.
First of all, node 3 is leaving a rejected msgApp... log indicating that it has rejected a message.
Nov 28 05:30:59.233 DEBG rejected msgApp [logterm: 7, index: 3641] from 2, logterm: Ok(0), index: 3641, from: 2, msg_index: 3641, msg_log_term: 7From the log above, we can see that node 3 is a follower node, node 2 is the newly elected leader node after the failure, and that the MsgAppend message trying to replicate the 3641th entry was rejected.
If we look up what function this log is output from, we can see that it is called from handle_append_entries, which we saw in Scenario 1 (the function that handles the MsgAppend messages that the follower receives from the leader).
pub fn handle_append_entries(&mut self, m: &Message) {
...
let mut to_send = Message::default();
to_send.to = m.from;
to_send.set_msg_type(MessageType::MsgAppendResponse);
...
if let Some((_, last_idx)) = self
.raft_log
.maybe_append(m.index, m.log_term, m.commit, &m.entries)
{
...
} else {
debug!(
self.logger,
"rejected msgApp [logterm: {msg_log_term}, index: {msg_index}] \
from {from}",
msg_log_term = m.log_term,
msg_index = m.index,
from = m.from;
"index" => m.index,
"logterm" => ?self.raft_log.term(m.index),
);
let hint_index = cmp::min(m.index, self.raft_log.last_index());
let (hint_index, hint_term) =
self.raft_log.find_conflict_by_term(hint_index, m.log_term);
if hint_term.is_none() {
fatal!(
self.logger,
"term({index}) must be valid",
index = hint_index
)
}
to_send.index = m.index;
to_send.reject = true;
to_send.reject_hint = hint_index;
to_send.log_term = hint_term.unwrap();
}
to_send.set_commit(self.raft_log.committed);
self.r.send(to_send, &mut self.msgs);
}If you look at the function, you can see that this log was output, which means that maybe_append returned None, which means that match_term returned False. This means that there is a mismatch between the logTerm in the message and the value of term in entry 3641.
So we find the point of conflict via term (find_conflict_by_term) and put the point of conflict (hint_index) into the reject_hint of the message and send it back to the reader in the form of an MsgAppendResponse message.
So what does the leader do with this rejected MsgAppendResponse message?
The leader node that rejected the message will leave a log that the MsgAppend was rejected, as shown below.
Nov 28 05:30:59.279 DEBG received msgAppend rejection, index: 3641, from: 3, reject_hint_term: 7, reject_hint_index: 3611So the next thing we need to look at is the function that receives this rejected MsgAppend message and outputs "received msgAppend rejection".
This function is called handle_append_response, and while the function itself is quite long, it's not that long when you cut it down to just what happens when an MsgAppend is rejected.
fn handle_append_response(&mut self, m: &Message) {
let mut next_probe_index: u64 = m.reject_hint;
...
if m.reject {
debug!(
self.r.logger,
"received msgAppend rejection";
"reject_hint_index" => m.reject_hint,
"reject_hint_term" => m.log_term,
"from" => m.from,
"index" => m.index,
);
if pr.maybe_decr_to(m.index, next_probe_index, m.request_snapshot) {
debug!(
self.r.logger,
"decreased progress of {}",
m.from;
"progress" => ?pr,
);
if pr.state == ProgressState::Replicate {
pr.become_probe();
}
self.send_append(m.from);
}
return;
}
...
}Take the reject_hint from the message and make it the next_probe_index, and call Progress.maybe_decr_to to decrement the progress. Indicate that Progress is in the probe state, and call send_append to send another MsgAppend message.
💡 ProgressState is an enum that represents the synchronization progress of each node. Under normal circumstances, it is "Replicate" if the node is replicating logs, "Probe" if the follower node does not know the last index that was replicated, and "Snapshot" if the node is in a probing state and is replicating logs to the follower by sending snapshots.
To summarize, to find the index (next_probe_index) of the log entry before the collision, we decrement the node's progress and send another MsgAppend message. This process is repeated until we find the Common log prefix of the leader and follower nodes.
Once the Common log prefix is found, log entries after that index are replicated in a unidirectional fashion from the leader to the follower and overwritten. This process can be seen in the maybe_send_append function.
The log entries obtained through RaftLog.entries are replicated into the SendAppend context as shown below. Here, max_msg_size is max_size_per_msg from Config, which defaults to 0. With RaftLog.entries, the max_size of the LMDBStorage.entries (persistent storage type, corresponding to T in RaftLog) argument is given 0, which, based on this comment, means that if you don't set it, it will synchronize log entries one by one when there is a mismatch in the logs of the leader and follower nodes.
After that, prepare_send_entries is used to prepare the MsgAppend message as described in the previous section, and Raft.send is used to replicate the entries to the follower node.
// tikv/raft-rs/blob/master/src/raft.rs
fn maybe_send_append(
&mut self,
to: u64,
pr: &mut Progress,
allow_empty: bool,
msgs: &mut Vec<Message>,
) -> bool {
...
let mut m = Message::default();
m.to = to;
if pr.pending_request_snapshot != INVALID_INDEX {
...
} else {
let ents = self.raft_log.entries(
pr.next_idx,
self.max_msg_size,
GetEntriesContext(GetEntriesFor::SendAppend {
to,
term: self.term,
aggressively: !allow_empty,
}),
);
...
let term = self.raft_log.term(pr.next_idx - 1);
match (term, ents) {
(Ok(term), Ok(mut ents)) => {
if self.batch_append && self.try_batching(to, msgs, pr, &mut ents) {
return true;
}
self.prepare_send_entries(&mut m, pr, term, ents)
}
...
}
}
self.send(m, msgs);
true
}There are a lot of logs missing in the middle, but you can see that after the synchronization between the leader and the follower has occurred through the above process from the *3612th entry to the *3642nd entry, the follower's progress state changes to Replicate and it starts sending and receiving Heartbeat messages normally.
2023-11-28 14:30:59,269 - INFO - Entries [3612, 3643) requested
Nov 28 05:30:59.269 DEBG Sending from 2 to 3, msg: Message { msg_type: MsgAppend, to: 3, from: 0, term: 0, log_term: 7, index: 3611, entries: [Entry { context: "1810", data: "{'key': '2292', 'value': '1'}", entry_type: EntryNormal, index: 3612, sync_log: false, term: 7 }], commit: 3642, commit_term: 0, snapshot: Snapshot { data: "None", metadata: None }, request_snapshot: 0, reject: false, reject_hint: 0, context: "None", deprecated_priority: 0, priority: 0 }, to: 3, from: 2
2023-11-28 14:30:59,259 - INFO - Entries [3613, 3643) requested
Nov 28 05:30:59.269 DEBG Sending from 2 to 3, msg: Message { msg_type: MsgAppend, to: 3, from: 0, term: 0, log_term: 7, index: 3612, entries: [Entry { context: "1811", data: "{'key': '2294', 'value': '1'}", entry_type: EntryNormal, index: 3613, sync_log: false, term: 7 }], commit: 3642, commit_term: 0, snapshot: Snapshot { data: "None", metadata: None }, request_snapshot: 0, reject: false, reject_hint: 0, context: "None", deprecated_priority: 0, priority: 0 }, to: 3, from: 2
2023-11-28 14:30:59,259 - INFO - Entries [3614, 3643) requested
Nov 28 05:30:59.269 DEBG Sending from 2 to 3, msg: Message { msg_type: MsgAppend, to: 3, from: 0, term: 0, log_term: 7, index: 3613, entries: [Entry { context: "1812", data: "{'key': '2295', 'value': '1'}", entry_type: EntryNormal, index: 3614, sync_log: false, term: 7 }], commit: 3642, commit_term: 0, snapshot: Snapshot { data: "None", metadata: None }, request_snapshot: 0, reject: false, reject_hint: 0, context: "None", deprecated_priority: 0, priority: 0 }, to: 3, from: 2
2023-11-28 14:30:59,259 - INFO - Entries [3615, 3643) requested
Nov 28 05:30:59.269 DEBG Sending from 2 to 3, msg: Message { msg_type: MsgAppend, to: 3, from: 0, term: 0, log_term: 7, index: 3614, entries: [Entry { context: "1813", data: "{'key': '2296', 'value': '1'}", entry_type: EntryNormal, index: 3615, sync_log: false, term: 7 }], commit: 3642, commit_term: 0, snapshot: Snapshot { data: "None", metadata: None }, request_snapshot: 0, reject: false, reject_hint: 0, context: "None", deprecated_priority: 0, priority: 0 }, to: 3, from: 2
...
2023-11-28 14:30:59,284 - INFO - Entries [3641, 3643) requested
Nov 28 05:30:59.283 DEBG Sending from 2 to 3, msg: Message { msg_type: MsgAppend, to: 3, from: 0, term: 0, log_term: 7, index: 3640, entries: [Entry { context: "1839", data: "{'key': '2457', 'value': '1'}", entry_type: EntryNormal, index: 3641, sync_log: false, term: 7 }], commit: 3642, commit_term: 0, snapshot: Snapshot { data: "None", metadata: None }, request_snapshot: 0, reject: false, reject_hint: 0, context: "None", deprecated_priority: 0, priority: 0 }, to: 3, from: 2
2023-11-28 14:30:59,284 - INFO - Entries [3642, 3643) requested
Nov 28 05:30:59.284 DEBG Sending from 2 to 3, msg: Message { msg_type: MsgAppend, to: 3, from: 0, term: 0, log_term: 7, index: 3641, entries: [Entry { context: "None", data: "None", entry_type: EntryNormal, index: 3642, sync_log: false, term: 12 }], commit: 3642, commit_term: 0, snapshot: Snapshot { data: "None", metadata: None }, request_snapshot: 0, reject: false, reject_hint: 0, context: "None", deprecated_priority: 0, priority: 0 }, to: 3, from: 2
Nov 28 05:31:01.635 DEBG Sending from 2 to 1, msg: Message { msg_type: MsgHeartbeat, to: 1, from: 0, term: 0, log_term: 0, index: 0, entries: [], commit: 3642, commit_term: 0, snapshot: Snapshot { data: "None", metadata: None }, request_snapshot: 0, reject: false, reject_hint: 0, context: "None", deprecated_priority: 0, priority: 0 }, to: 1, from: 2
Nov 28 05:31:01.635 DEBG Sending from 2 to 3, msg: Message { msg_type: MsgHeartbeat, to: 3, from: 0, term: 0, log_term: 0, index: 0, entries: [], commit: 3642, commit_term: 0, snapshot: Snapshot { data: "None", metadata: None }, request_snapshot: 0, reject: false, reject_hint: 0, context: "None", deprecated_priority: 0, priority: 0 }, to: 3, from: 2
2023-11-28 14:31:01,6373 - Electing a leader
In Scenario 2, we could tell from the increase in the term value that the leader election was caused by a network failure, but in this scenario we'll take a closer look at the leader election process.
To see what logs would be taken if the leader failed, we'll simply create a cluster of 3 nodes, force the leader process to shut down, and look at the logs of the process that is newly elected leader.
To summarize the logs, after the leader node shuts down, node 3 starts the election and transitions to the Candidate state and sends a MsgRestVote message to the other voters. The process can be summarized as: you receive a MsgRequestVoteResponse message from node 2, you are elected as the new leader because you received a majority of the votes for yourself, you increase the term value to 2, and you send a special kind of message (an empty MsgAppend) to announce that you are the elected leader.
💡 A follower node that has not received a heartbeat message by election_tick will start voting. In this case, to avoid split vote, election_tick is determined to be a random value between min_election_tick and max_election_tick each time. Therefore, after the leader node is terminated, any of the remaining two nodes can become the leader node, and it will be elected as the node with the smaller election_tick.
Nov 29 01:30:30.210 INFO starting a new election, term: 1
Nov 29 01:30:30.210 DEBG reset election timeout 16 -> 10 at 0, election_elapsed: 0, timeout: 10, prev_timeout: 16
Nov 29 01:30:30.210 INFO became candidate at term 2, term: 2
Nov 29 01:30:30.210 DEBG Sending from 3 to 1, msg: Message { msg_type: MsgRequestVote, to: 1, from: 0, term: 2, log_term: 1, index: 3, entries: [], commit: 3, commit_term: 1, snapshot: Snapshot { data: "None", metadata: None }, request_snapshot: 0, reject: false, reject_hint: 0, context: "None", deprecated_priority: 0, priority: 0 }, to: 1, from: 3
Nov 29 01:30:30.210 DEBG Sending from 3 to 2, msg: Message { msg_type: MsgRequestVote, to: 2, from: 0, term: 2, log_term: 1, index: 3, entries: [], commit: 3, commit_term: 1, snapshot: Snapshot { data: "None", metadata: None }, request_snapshot: 0, reject: false, reject_hint: 0, context: "None", deprecated_priority: 0, priority: 0 }, to: 2, from: 3
Nov 29 01:30:30.211 INFO broadcasting vote request, to: [1, 2], log_index: 3, log_term: 1, term: 2, type: MsgRequestVote
2023-11-29 10:30:30,217 - WARNING - Failed to connect to node 1 elapsed from first failure: 0.0000s. Err message: <AioRpcError of RPC that terminated with:
status = StatusCode.UNAVAILABLE
details = "failed to connect to all addresses; last error: UNKNOWN: ipv4:127.0.0.1:60061: Failed to connect to remote host: Connection refused"
debug_error_string = "UNKNOWN:failed to connect to all addresses; last error: UNKNOWN: ipv4:127.0.0.1:60061: Failed to connect to remote host: Connection refused {created_time:"2023-11-29T10:30:30.216855+09:00", grpc_status:14}"
>
2023-11-29 10:30:30,222 - DEBUG - Node 3 received Raft message from the node 2, Message: Message { msg_type: MsgRequestVoteResponse, to: 3, from: 2, term: 2, log_term: 0, index: 0, entries: [], commit: 0, commit_term: 0, snapshot: Snapshot { data: "None", metadata: Some(SnapshotMetadata { conf_state: Some(ConfState { voters: [], learners: [], voters_outgoing: [], learners_next: [], auto_leave: false }), index: 0, term: 0 }) }, request_snapshot: 0, reject: false, reject_hint: 0, context: "None", deprecated_priority: 0, priority: 0 }
Nov 29 01:30:30.223 INFO received votes response, term: 2, type: MsgRequestVoteResponse, approvals: 2, rejections: 0, from: 2, vote: true
Nov 29 01:30:30.223 TRCE ENTER become_leader
Nov 29 01:30:30.223 DEBG reset election timeout 10 -> 17 at 0, election_elapsed: 0, timeout: 17, prev_timeout: 10
Nov 29 01:30:30.223 TRCE Entries being appended to unstable list, ents: Entry { context: "None", data: "None", entry_type: EntryNormal, index: 4, sync_log: false, term: 2 }
Nov 29 01:30:30.223 INFO became leader at term 2, term: 2
Nov 29 01:30:30.223 TRCE EXIT become_leader
Nov 29 01:30:30.223 DEBG Sending from 3 to 1, msg: Message { msg_type: MsgAppend, to: 1, from: 0, term: 0, log_term: 1, index: 3, entries: [Entry { context: "None", data: "None", entry_type: EntryNormal, index: 4, sync_log: false, term: 2 }], commit: 3, commit_term: 0, snapshot: Snapshot { data: "None", metadata: None }, request_snapshot: 0, reject: false, reject_hint: 0, context: "None", deprecated_priority: 0, priority: 0 }, to: 1, from: 3
Nov 29 01:30:30.223 DEBG Sending from 3 to 2, msg: Message { msg_type: MsgAppend, to: 2, from: 0, term: 0, log_term: 1, index: 3, entries: [Entry { context: "None", data: "None", entry_type: EntryNormal, index: 4, sync_log: false, term: 2 }], commit: 3, commit_term: 0, snapshot: Snapshot { data: "None", metadata: None }, request_snapshot: 0, reject: false, reject_hint: 0, context: "None", deprecated_priority: 0, priority: 0 }, to: 2, from: 3Let's take a look at the logs to see what's going on in the code.
First of all, the function that is printing the log "starting a new election" is hup.
hupis called during the processing of messages of typeMsgHupfromstepandMsgTimeoutNowfromstep_follower`.
Note that the MsgTimeoutNow message is the message type used for Leader transfer, not Leader election. This means that when the leader receives the MsgTransferLeader message, it will send a message of type MsgTimeoutNow to its followers and the hup function will be executed with the transfer_leader flag set to True. While Leader election is the process of electing a new leader in the event of a leader failure, Leader transfer is the process of a leader process transferring leadership to another follower process.
So we can see that the message we need to follow now is MsgHup. We can guess that it was the tick_election function below that put in the MsgHup message because we didn't get a Heartbeat after the election_tick, so we started electing a leader.
Remember how we called self.raw_node.tick() every tick_timer on RaftNode? This RawNode.tick allows the node to step an MsgHup message to itself if the election_elapsed has passed the randomized_election_timeout. (Randomizing the election_elapsed here is to prevent a situation where all nodes start voting at the same time and all nodes vote for themselves).
// raw_node.rs
pub fn tick(&mut self) -> bool {
self.raft.tick()
}
// raft.rs
pub fn tick(&mut self) -> bool {
match self.state {
StateRole::Follower | StateRole::PreCandidate | StateRole::Candidate => {
self.tick_election()
}
StateRole::Leader => self.tick_heartbeat(),
}
}
// raft.rs
pub fn tick_election(&mut self) -> bool {
self.election_elapsed += 1;
if !self.pass_election_timeout() || !self.promotable {
return false;
}
self.election_elapsed = 0;
let m = new_message(INVALID_ID, MessageType::MsgHup, Some(self.id));
let _ = self.step(m);
true
}
// raft.rs
pub fn step(&mut self, m: Message) -> Result<()> {
...
match m.get_msg_type() {
...
MessageType::MsgHup => {
self.hup(false)
},
}
}
// raft.rs
pub fn pass_election_timeout(&self) -> bool {
self.election_elapsed >= self.randomized_election_timeout
}The hup function runs the campaign function with the CAMPAIGN_ELECTION type, as shown below to summarize.
// tikv/raft-rs/blob/master/src/raft.rs
fn hup(&mut self, transfer_leader: bool) {
...
info!(
self.logger,
"starting a new election";
"term" => self.term,
);
...
self.campaign(CAMPAIGN_ELECTION);
}The campaign function transitions its own state to the Candidate state and starts voting, as shown below.
First of all, self_id is the node's own id, as the name suggests, so self.poll(self_id, vote_msg, true) means to vote for yourself.
If the result is VoteResult::Won, then the node wins the vote as it is and returns as the leader.
So you can see that messages like MsgRequestVote, MsgRequestVoteResponse, etc. will not be sent back and forth in a single-node cluster.
But of course, this scenario is not the case because it is not a single-node cluster.
// tikv/raft-rs/blob/master/src/raft.rs
pub fn campaign(&mut self, campaign_type: &'static [u8]) {
let (vote_msg, term) = if campaign_type == CAMPAIGN_PRE_ELECTION {
...
} else {
self.become_candidate();
(MessageType::MsgRequestVote, self.term)
};
let self_id = self.id;
if VoteResult::Won == self.poll(self_id, vote_msg, true) {
// We won the election after voting for ourselves (which must mean that
// this is a single-node cluster).
return;
}
...
}Before we dive into the latter part of campaign, let's take a look at how poll works.
The poll is a function that calls record_vote, tally_votes, and depending on the result of the poll, if it wins the vote, it transitions to the leader node and broadcasts (bcast_append) that it is the new leader of the cluster.
If it loses the vote, it transitions to a follower node, and if the result is Pending, it returns without doing anything.
// tikv/raft-rs/blob/master/src/raft.rs
fn poll(&mut self, from: u64, t: MessageType, vote: bool) -> VoteResult {
self.prs.record_vote(from, vote);
let (gr, rj, res) = self.prs.tally_votes();
if from != self.id {
info!(
self.logger,
"received votes response";
"vote" => vote,
"from" => from,
"rejections" => rj,
"approvals" => gr,
"type" => ?t,
"term" => self.term,
);
}
match res {
VoteResult::Won => {
if self.state == StateRole::PreCandidate {
self.campaign(CAMPAIGN_ELECTION);
} else {
self.become_leader();
self.bcast_append();
}
}
VoteResult::Lost => {
let term = self.term;
self.become_follower(term, INVALID_ID);
}
VoteResult::Pending => (),
}
res
}The role of record_vote is quite simple. It records in the hashmap object votes of the ProgressTracker when a node with the value id has voted for itself.
// tikv/raft-rs/blob/master/src/tracker.rs
pub fn record_vote(&mut self, id: u64, vote: bool) {
self.votes.entry(id).or_insert(vote);
}Let's look at tally_votes. You can see that the hashmap votes is counting the number of nodes that voted for you and the number of nodes that rejected you, and returning them as a tuple.
💡 The word "tally" refers to the act of counting or aggregating points, so "tally_votes" is a function that counts and aggregates votes.
// tikv/raft-rs/blob/master/src/tracker.rs
pub fn tally_votes(&self) -> (usize, usize, VoteResult) {
let (mut granted, mut rejected) = (0, 0);
for (id, vote) in &self.votes {
if !self.conf.voters.contains(*id) {
continue;
}
if *vote {
granted += 1;
} else {
rejected += 1;
}
}
let result = self.vote_result(&self.votes);
(granted, rejected, result)
}Let's take a look at how we determine the outcome of a vote.
For a joint quorum, we need to get the consensus of both quorums (Incoming quorum, Outgoing quorum) to win the vote.
So we need to look at the three vote_result functions below.
In tracker.rs, we pass as an argument the callback function check, which allows the node id to know if the hashmap votes has voted for it.
In joint.rs, we return VoteResult::Won only if both configurations win, and VoteResult::Lost if either side loses the vote. Otherwise, we return VoteResult::Pending.
The actual counting of votes is done in vote_result in majority.rs.
It counts the number of nodes in the cluster that voted for itself and the number of nodes that did not vote, and returns VoteResult::Won if more than a majority of the nodes agree, VoteResult::Pending if the majority is greater than a majority when including nodes that did not get a majority of the votes but failed to send a response, or VoteResult::Lost otherwise.
// tracker.rs
pub fn vote_result(&self, votes: &HashMap<u64, bool>) -> VoteResult {
self.conf.voters.vote_result(|id| votes.get(&id).cloned())
}
// joint.rs
pub fn vote_result(&self, check: impl Fn(u64) -> Option<bool>) -> VoteResult {
let i = self.incoming.vote_result(&check);
let o = self.outgoing.vote_result(check);
match (i, o) {
// It won if won in both.
(VoteResult::Won, VoteResult::Won) => VoteResult::Won,
// It lost if lost in either.
(VoteResult::Lost, _) | (_, VoteResult::Lost) => VoteResult::Lost,
// It remains pending if pending in both or just won in one side.
_ => VoteResult::Pending,
}
}
// majority.rs
pub fn vote_result(&self, check: impl Fn(u64) -> Option<bool>) -> VoteResult {
...
let (mut yes, mut missing) = (0, 0);
for v in &self.voters {
match check(*v) {
Some(true) => yes += 1,
None => missing += 1,
_ => (),
}
}
let q = crate::majority(self.voters.len());
if yes >= q {
VoteResult::Won
} else if yes + missing >= q {
VoteResult::Pending
} else {
VoteResult::Lost
}
}
// util.rs
pub fn majority(total: usize) -> usize {
(total / 2) + 1
}We've seen how the voting process is based on the votes hashmap, but before this can happen, this hashmap needs to be updated appropriately via the MsgRequestVote, MsgRequestVoteResponse messages.
So, let's continue following the campaign function.
We can see that the campaign function is creating messages of type MsgRequestVote and sending them to voters.
So next, let's follow the handler for the MsgRequestVote message.
// tikv/raft-rs/blob/master/src/raft.rs
pub fn campaign(&mut self, campaign_type: &'static [u8]) {
let (vote_msg, term) = if campaign_type == CAMPAIGN_PRE_ELECTION {
...
} else {
self.become_candidate();
(MessageType::MsgRequestVote, self.term)
};
let self_id = self.id;
if VoteResult::Won == self.poll(self_id, vote_msg, true) {
// We won the election after voting for ourselves (which must mean that
// this is a single-node cluster).
return;
}
// Only send vote request to voters.
for id in self.prs.conf().voters().ids().iter() {
if id == self_id {
continue;
}
...
let mut m = new_message(id, vote_msg, None);
m.term = term;
m.index = self.raft_log.last_index();
m.log_term = self.raft_log.last_term();
m.commit = commit;
m.commit_term = commit_term;
...
self.r.send(m, &mut self.msgs);
}
...
}
At first glance, it seems complicated, but at the end of the day, what the handler of MsgRestVote does is create and send a message to agree or disagree with this vote.
Based on the vote_resp_msg_type, the type we sent is MsgRequestVote, so the type of the response message will be MsgRequestVoteResponse. (We'll skip describing the prevote algorithm in this article)
So let's see when a node agrees to vote and when it disagrees. If you peruse the code along with the comments, you'll notice that three conditions must be met for a node to agree to a vote.
-
can_vote
is *true* (either you already voted for the node, or you don't know theleader_idfor thisterm` and haven't voted yet) -
self.raft_log.is_up_to_dateis true (the message'stermvalue is greater thanRaftLog.last_termor, if equal, the message's index is greater thanRaftLog.last_index) -
the index of the message is greater than
RaftLog.last_index, or has a higher priority.
If these three conditions are met, we send a message that we agree to vote, and if none of them are met, we reject the vote.
Now let's move on to the receiver of the MsgRequestVoteResponse.
// raft.rs
pub fn step(&mut self, m: Message) -> Result<()> {
...
match m.get_msg_type() {
MessageType::MsgRequestVote => {
// We can vote if this is a repeat of a vote we've already cast...
let can_vote = (self.vote == m.from) ||
// ...we haven't voted and we don't think there's a leader yet in this term...
(self.vote == INVALID_ID && self.leader_id == INVALID_ID)
// ...and we believe the candidate is up to date.
if can_vote
&& self.raft_log.is_up_to_date(m.index, m.log_term)
&& (m.index > self.raft_log.last_index() || self.priority <= get_priority(&m))
{
self.log_vote_approve(&m);
let mut to_send =
new_message(m.from, vote_resp_msg_type(m.get_msg_type()), None);
to_send.reject = false;
to_send.term = m.term;
self.r.send(to_send, &mut self.msgs);
if m.get_msg_type() == MessageType::MsgRequestVote {
// Only record real votes.
self.election_elapsed = 0;
self.vote = m.from;
}
} else {
self.log_vote_reject(&m);
let mut to_send =
new_message(m.from, vote_resp_msg_type(m.get_msg_type()), None);
to_send.reject = true;
to_send.term = self.term;
let (commit, commit_term) = self.raft_log.commit_info();
to_send.commit = commit;
to_send.commit_term = commit_term;
self.r.send(to_send, &mut self.msgs);
self.maybe_commit_by_vote(&m);
}
}
}
}
// raft.rs
pub fn vote_resp_msg_type(t: MessageType) -> MessageType {
match t {
MessageType::MsgRequestVote => MessageType::MsgRequestVoteResponse,
MessageType::MsgRequestPreVote => MessageType::MsgRequestPreVoteResponse,
_ => panic!("Not a vote message: {:?}", t),
}
}
// raft_log.rs
pub fn is_up_to_date(&self, last_index: u64, term: u64) -> bool {
term > self.last_term() || (term == self.last_term() && last_index >= self.last_index())
}The MsgRequestVoteResponse message handler is very simple!
It calls the poll function we saw earlier to update the votes hashmap and update the StateRole if the vote has been decided.
// tikv/raft-rs/blob/master/src/raft.rs
fn step_candidate(&mut self, m: Message) -> Result<()> {
match m.get_msg_type() {
...
MessageType::MsgRequestVoteResponse => {
...
self.poll(m.from, m.get_msg_type(), !m.reject);
self.maybe_commit_by_vote(&m);
}
}
}Summary
In this article, we looked at the code architecture based on the types used in RAFT-RS, and then followed and analyzed the code of a RAFT implementation in three basic scenarios. We hope that this article has helped you expand your understanding of the RAFT module. In the next installment, we'll take a deeper look at how the RAFT implementation works with more scenarios.
Thanks 😊
This post auto translated from Korean



